Трансформеры: Подробное Руководство по Архитектуре и Механизмам
Детальное пошаговое объяснение принципов работы, математических основ и архитектуры трансформеров
Содержание
- Введение: История и значимость трансформеров
- Обзор архитектуры трансформера
- Системы векторных представлений (Embeddings)
- Механизм внимания (Self-Attention)
- Многоголовое внимание (Multi-Head Attention)
- Позиционное кодирование (Positional Encoding)
- Полносвязные сети прямого распространения (Feed-Forward Networks)
- Архитектура энкодер-декодер
- Нормализация слоев и остаточные связи
- Пошаговый анализ вычислительного процесса
- Применения трансформеров
- Пример работы и реализации
- Заключение и дальнейшие направления
Введение: История и значимость трансформеров
Архитектура трансформеров, впервые представленная в основополагающей статье "Attention Is All You Need" в 2017 году исследователями Google, произвела революцию в области обработки естественного языка (NLP) и глубокого обучения. В отличие от предшествующих архитектур, таких как рекуррентные нейронные сети (RNN) и сверточные нейронные сети (CNN), трансформеры полностью опираются на механизм внимания, не используя рекуррентность или свертки.
Ключевое преимущество трансформеров заключается в их способности обрабатывать последовательности параллельно, что значительно ускоряет обучение и вывод. Они также эффективно улавливают дальние зависимости в данных, что критически важно для понимания контекста в языковых моделях.
Трансформеры стали фундаментальной архитектурой для современных языковых моделей, таких как GPT (Generative Pre-trained Transformer), BERT (Bidirectional Encoder Representations from Transformers), T5 и многих других. Эти модели достигли впечатляющих результатов в различных задачах NLP, включая машинный перевод, ответы на вопросы, генерацию текста и анализ настроений.
Историческая справка: До появления трансформеров, модели, основанные на RNN (такие как LSTM и GRU), были стандартом для обработки последовательностей. Однако они страдали от проблемы исчезающего градиента при обработке длинных последовательностей и не могли быть распараллелены, что делало их обучение медленным.
Обзор архитектуры трансформера
Трансформер представляет собой нейросетевую архитектуру, основанную на механизме самовнимания (self-attention). Базовая архитектура состоит из двух основных компонентов: энкодера и декодера, хотя в некоторых реализациях (например, GPT) используется только декодер, а в других (например, BERT) – только энкодер.
Основные компоненты трансформера включают:
- Системы векторных представлений (Embeddings) – преобразуют входные токены в векторные представления.
- Позиционное кодирование (Positional Encoding) – добавляет информацию о позиции токена в последовательности.
- Многоголовое внимание (Multi-Head Attention) – позволяет модели фокусироваться на различных аспектах входной последовательности.
- Полносвязная сеть прямого распространения (Feed-Forward Network) – обрабатывает каждую позицию независимо.
- Нормализация слоев (Layer Normalization) – стабилизирует процесс обучения.
- Остаточные связи (Residual Connections) – помогают преодолеть проблему исчезающего градиента.
Общая архитектура трансформера выглядит следующим образом:
В базовой модели энкодер и декодер состоят из стека идентичных слоев (N = 6 в оригинальной работе). Каждый слой энкодера содержит два подслоя: механизм многоголового самовнимания и полносвязную сеть. Декодер добавляет третий подслой, который выполняет многоголовое внимание над выходом энкодера. Каждый подслой в энкодере и декодере заключен в остаточное соединение и последующую нормализацию слоя.
Системы векторных представлений (Embeddings)
Первым шагом в работе трансформера является преобразование входных токенов (слов или подслов) в векторные представления фиксированной размерности. Этот процесс называется вложением (embedding) и является обучаемым компонентом модели.
В контексте NLP, токены – это единицы текста, которые могут быть словами, частями слов или даже отдельными символами. Каждому токену присваивается уникальный идентификатор, который затем преобразуется в вектор с помощью матрицы вложений:
\[ E_{\text{token}} = \text{Embedding}(\text{token_id}) \in \mathbb{R}^{d_{\text{model}}} \]
где \(d_{\text{model}}\) – размерность векторного представления (например, 512 в оригинальной работе).
Процесс формирования вложений может быть представлен как поиск в таблице (lookup table), где каждому идентификатору токена соответствует вектор размерности \(d_{\text{model}}\). Эта таблица – обучаемая матрица параметров модели.
Важно отметить, что в трансформерах обычно используется общая матрица вложений как для входного, так и для выходного слоя (с масштабированием). Это уменьшает количество параметров и обеспечивает согласованность представлений.
Пример процесса вложения:
1. Допустим, у нас есть предложение: "Трансформеры используют механизм внимания"
2. После токенизации оно может быть представлено как: ["Трансформеры", "используют", "механизм", "внимания"]
3. Каждому токену присваивается уникальный ID: [1024, 2048, 3072, 4096]
4. Каждый ID преобразуется в вектор размерности d_model=512 с помощью матрицы вложений
5. В результате получаем матрицу размерности [4, 512], где каждая строка соответствует векторному представлению токена
Механизм внимания (Self-Attention)
Механизм внимания (self-attention) – ключевой компонент архитектуры трансформера, позволяющий модели фокусироваться на различных частях входной последовательности при обработке каждого токена. Это позволяет улавливать дальние зависимости и контекстуальные связи между токенами.
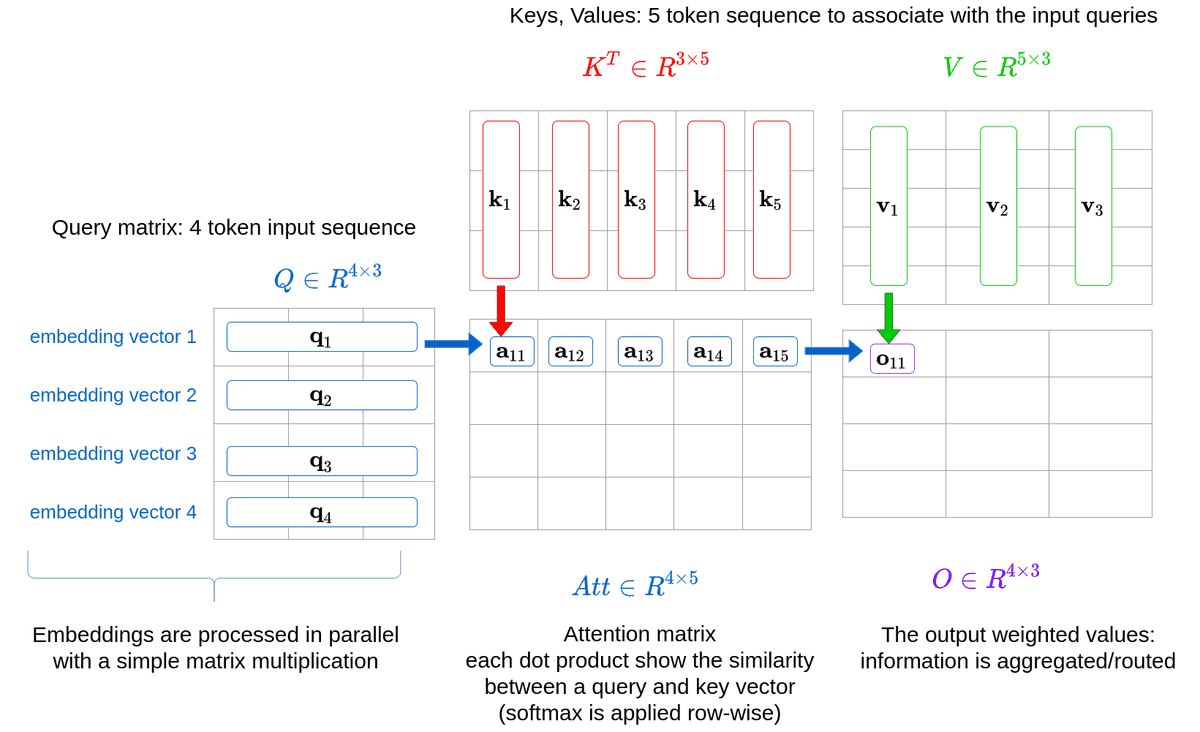
В общем виде, механизм внимания можно описать как отображение запроса (query) и набора пар ключ-значение (key-value) в выходное представление, где все векторы запроса, ключа, значения и выхода имеют определенную размерность.
Математическая формулировка механизма внимания
Масштабированное точечное произведение (Scaled Dot-Product Attention) – реализация механизма внимания, используемая в трансформерах:
\[ \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V \]
Где:
- \(Q\) – матрица запросов размерности \([seq\_len, d_k]\)
- \(K\) – матрица ключей размерности \([seq\_len, d_k]\)
- \(V\) – матрица значений размерности \([seq\_len, d_v]\)
- \(d_k\) – размерность векторов запроса и ключа
- \(d_v\) – размерность векторов значений
- \(\sqrt{d_k}\) – масштабирующий фактор для стабилизации градиентов
Процесс вычисления внимания можно разбить на следующие шаги:
- Вычисление "сырых" весов внимания как точечного произведения между запросами и ключами: \(QK^T\)
- Масштабирование этих весов делением на \(\sqrt{d_k}\) для стабилизации градиентов
- Применение softmax для получения вероятностного распределения весов внимания
- Взвешенное суммирование значений по этим весам для получения выхода
Интуитивно: если вектор запроса и вектор ключа имеют высокую косинусную схожесть (то есть, их точечное произведение велико), то соответствующее значение получит больший вес.
Маскированное внимание (Masked Attention)
В декодере трансформера используется маскированное внимание, которое предотвращает доступ к "будущим" токенам при генерации последовательности. Это реализуется путем установки недопустимых связей (будущих токенов) в -∞ перед применением softmax:
\[ \text{MaskedAttention}(Q, K, V) = \text{softmax}\left(\frac{QK^T + M}{\sqrt{d_k}}\right)V \]
где \(M\) – маска, в которой элементы, соответствующие недопустимым связям, равны \(-\infty\), а остальные – 0.
Пример расчета механизма внимания:
Предположим, у нас есть последовательность из 3 токенов с размерностью \(d_k = d_v = 4\).
1. Матрица запросов Q:
Q = [[1, 0, 1, 0],
[0, 1, 0, 1],
[1, 1, 0, 0]]
2. Матрица ключей K:
K = [[0, 1, 0, 1],
[1, 0, 1, 0],
[0, 0, 1, 1]]
3. Матрица значений V:
V = [[0.1, 0.3, 0.5, 0.7],
[0.2, 0.4, 0.6, 0.8],
[0.3, 0.5, 0.7, 0.9]]
4. Вычисляем матрицу "сырых" весов внимания: \(QK^T = Q \cdot K^T\)
QK^T = [[0, 1, 1],
[1, 0, 1],
[1, 1, 0]]
5. Масштабируем матрицу: \(QK^T / \sqrt{d_k} = QK^T / 2\)
QK^T / 2 = [[0, 0.5, 0.5],
[0.5, 0, 0.5],
[0.5, 0.5, 0]]
6. Применяем softmax для получения весов внимания:
softmax(QK^T / 2) ≈ [[0.25, 0.375, 0.375],
[0.375, 0.25, 0.375],
[0.375, 0.375, 0.25]]
7. Взвешенная сумма значений: \(\text{softmax}(QK^T / 2) \cdot V\)
Output = [[0.2, 0.4, 0.6, 0.8],
[0.2, 0.4, 0.6, 0.8],
[0.2, 0.4, 0.6, 0.8]]
Важно: Масштабирование на \(\sqrt{d_k}\) предотвращает проблему исчезающих градиентов при больших значениях \(d_k\). Без этого масштабирования, при большом \(d_k\) точечное произведение может давать очень большие значения, что приводит к очень малым градиентам после применения softmax.
Многоголовое внимание (Multi-Head Attention)
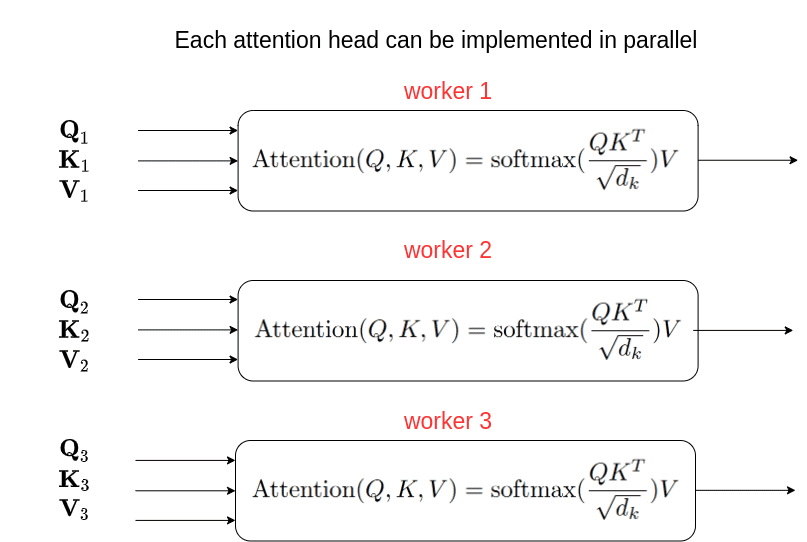
Многоголовое внимание (Multi-Head Attention) позволяет трансформеру одновременно фокусироваться на информации из разных представлений в разных позициях. Вместо выполнения одной операции внимания с векторами запроса, ключа и значения размерности \(d_{\text{model}}\), многоголовое внимание линейно проецирует эти векторы \(h\) раз с разными проекциями.
Математическая формулировка многоголового внимания
\[ \text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, \text{head}_2, ..., \text{head}_h)W^O \]
\[ \text{where} \; \text{head}_i = \text{Attention}(QW_i^Q, KW_i^K, VW_i^V) \]
Где:
- \(W_i^Q \in \mathbb{R}^{d_{\text{model}} \times d_k}\) – проекционная матрица для запросов
- \(W_i^K \in \mathbb{R}^{d_{\text{model}} \times d_k}\) – проекционная матрица для ключей
- \(W_i^V \in \mathbb{R}^{d_{\text{model}} \times d_v}\) – проекционная матрица для значений
- \(W^O \in \mathbb{R}^{hd_v \times d_{\text{model}}}\) – проекционная матрица для объединения выходов всех голов
Обычно используется \(d_k = d_v = d_{\text{model}}/h\), что сохраняет общую вычислительную сложность похожей на обычное внимание с полной размерностью.
Особенности и инсайты многоголового внимания
Использование нескольких "голов" внимания позволяет модели получить следующие преимущества:
- Параллельная обработка различных аспектов информации из одной и той же последовательности.
- Улавливание разных типов зависимостей между токенами (например, синтаксических, семантических, и т.д.).
- Более эффективное использование параметрической емкости модели.
Исследования показывают, что разные головы внимания специализируются на разных типах связей:
- Позиционные головы – уделяют внимание преимущественно соседним токенам.
- Синтаксические головы – указывают на токены с определенными синтаксическими отношениями.
- Головы, указывающие на редкие слова – фокусируются на необычных или редко встречающихся токенах.
Важное замечание: Несмотря на кажущуюся независимость, головы внимания часто обучаются фокусироваться на одних и тех же подпространствах, что позволяет эффективно прореживать (pruning) некоторые головы без существенной потери производительности модели.
Позиционное кодирование (Positional Encoding)
Поскольку трансформер не содержит рекуррентности или свертки, он должен каким-то образом учитывать порядок элементов в последовательности. Для этого к входным векторным представлениям добавляется информация о позиции токена – позиционное кодирование.
В оригинальной работе используется детерминированное позиционное кодирование, основанное на синусоидальных функциях:
\[ PE_{(pos, 2i)} = \sin\left(\frac{pos}{10000^{2i/d_{\text{model}}}}\right) \]
\[ PE_{(pos, 2i+1)} = \cos\left(\frac{pos}{10000^{2i/d_{\text{model}}}}\right) \]
Где:
- \(pos\) – позиция токена в последовательности
- \(i\) – размерность вектора позиционного кодирования
- \(d_{\text{model}}\) – размерность векторного представления
Такое позиционное кодирование имеет несколько важных свойств:
- Уникальный паттерн для каждой позиции
- Детерминированность (не требует обучения)
- Возможность экстраполяции на последовательности длиннее, чем встречались при обучении
- Синусоидальные функции разной частоты обеспечивают представление как абсолютной, так и относительной позиции
В современных реализациях трансформеров часто используются обучаемые позиционные вложения вместо фиксированных синусоидальных функций.
Пример позиционного кодирования:
Для последовательности из 5 токенов и \(d_{\text{model}} = 4\), позиционное кодирование может выглядеть так:
PE = [[0.0000, 1.0000, 0.0000, 1.0000], // позиция 0 [0.8415, 0.5403, 0.0464, 0.9989], // позиция 1 [0.9093, -0.4161, 0.0927, 0.9957], // позиция 2 [0.1411, -0.9900, 0.1388, 0.9903], // позиция 3 [-0.7568, -0.6536, 0.1846, 0.9828]] // позиция 4
Полносвязные сети прямого распространения (Feed-Forward Networks)
Каждый слой энкодера и декодера трансформера содержит полносвязную сеть прямого распространения (Feed-Forward Network, FFN), которая применяется к каждой позиции отдельно и одинаково. Эта сеть состоит из двух линейных преобразований с активацией ReLU между ними:
\[ \text{FFN}(x) = \max(0, xW_1 + b_1)W_2 + b_2 \]
Где:
- \(W_1 \in \mathbb{R}^{d_{\text{model}} \times d_{\text{ff}}}\) и \(b_1 \in \mathbb{R}^{d_{\text{ff}}}\) – параметры первого линейного преобразования
- \(W_2 \in \mathbb{R}^{d_{\text{ff}} \times d_{\text{model}}}\) и \(b_2 \in \mathbb{R}^{d_{\text{model}}}\) – параметры второго линейного преобразования
- \(d_{\text{ff}}\) – внутренняя размерность сети (обычно в 4 раза больше, чем \(d_{\text{model}}\))
FFN можно рассматривать как два свертки размером 1 с активацией ReLU между ними. Внутренняя размерность \(d_{\text{ff}}\) обычно составляет 2048 для базовой модели и 4096 для большой модели.
Важность FFN:
- Обеспечивает нелинейность в модели
- Позволяет обрабатывать каждую позицию независимо после учета контекста через механизм внимания
- Увеличивает параметрическую емкость модели
Примечание: В новых версиях трансформеров часто используются другие активации, такие как GELU (Gaussian Error Linear Unit) вместо ReLU, что может улучшить производительность модели.
Архитектура энкодер-декодер
Оригинальная архитектура трансформера состоит из энкодера и декодера, которые обрабатывают входную и выходную последовательности соответственно.
Энкодер (Encoder)
Энкодер трансформера состоит из стека N идентичных слоев (N = 6 в оригинальной работе). Каждый слой содержит два подслоя:
- Механизм многоголового самовнимания (Multi-Head Self-Attention)
- Полносвязная сеть прямого распространения (Feed-Forward Network)
Вокруг каждого подслоя применяется остаточное соединение, за которым следует нормализация слоя:
\[ \text{LayerNorm}(x + \text{Sublayer}(x)) \]
Основная задача энкодера – создать контекстуально-обогащенные представления входной последовательности. Каждый токен на выходе энкодера содержит информацию о всей входной последовательности, благодаря механизму самовнимания.
Декодер (Decoder)
Декодер также состоит из стека N идентичных слоев. Каждый слой декодера содержит три подслоя:
- Маскированный механизм многоголового самовнимания (Masked Multi-Head Self-Attention)
- Механизм многоголового перекрестного внимания (Multi-Head Cross-Attention) над выходом энкодера
- Полносвязная сеть прямого распространения (Feed-Forward Network)
Как и в энкодере, вокруг каждого подслоя применяется остаточное соединение и нормализация слоя.
Отличительная особенность декодера – использование маскированного самовнимания в первом подслое, что предотвращает доступ к будущим позициям и обеспечивает автореграссивную генерацию.
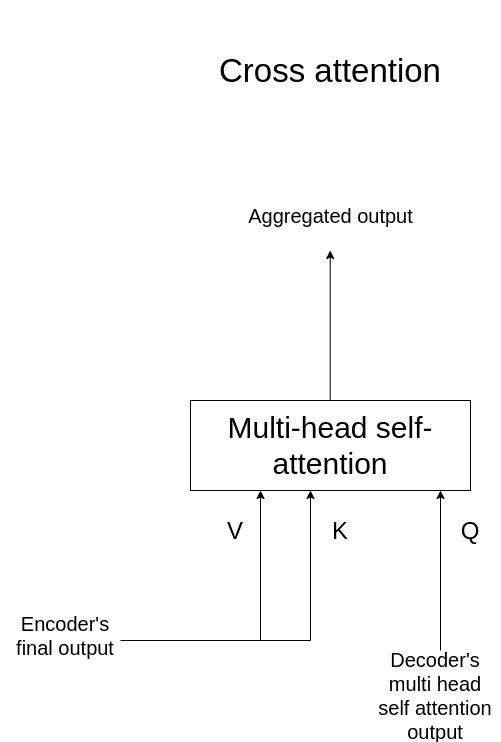
Перекрестное внимание (Cross-Attention)
Перекрестное внимание – механизм, позволяющий декодеру фокусироваться на соответствующих частях входной последовательности, обработанной энкодером:
\[ \text{CrossAttention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V \]
Где запросы (Q) поступают из предыдущего слоя декодера, а ключи (K) и значения (V) – из выхода энкодера.
Перекрестное внимание позволяет модели создавать связи между входной и выходной последовательностями, что критически важно для таких задач, как машинный перевод.
Важно: Исследования показывают, что перекрестное внимание является наиболее критичным компонентом для трансформеров в задачах, требующих согласования входной и выходной последовательностей. Прореживание головок в перекрестном внимании приводит к значительно большему падению производительности, чем прореживание головок в механизмах самовнимания.
Нормализация слоев и остаточные связи
Трансформеры используют два важных механизма для стабилизации обучения: нормализацию слоев (Layer Normalization) и остаточные связи (Residual Connections).
Нормализация слоев применяется к каждой позиции отдельно и нормализует активации по признакам:
\[ \mu_n = \frac{1}{d_{\text{model}}} \sum_{i=1}^{d_{\text{model}}} x_{ni} \]
\[ \sigma_n^2 = \frac{1}{d_{\text{model}}} \sum_{i=1}^{d_{\text{model}}} (x_{ni} - \mu_n)^2 \]
\[ \text{LayerNorm}(x_n) = \gamma \cdot \frac{x_n - \mu_n}{\sqrt{\sigma_n^2 + \epsilon}} + \beta \]
Где \(\gamma\) и \(\beta\) – обучаемые параметры масштабирования и сдвига, а \(\epsilon\) – малая константа для численной стабильности.
Остаточные связи (или skip-connections) позволяют добавлять вход подслоя к его выходу:
\[ \text{Output} = \text{LayerNorm}(x + \text{Sublayer}(x)) \]
Преимущества этих механизмов:
- Нормализация слоев: стабилизирует обучение, уменьшает зависимость от инициализации, ускоряет сходимость.
- Остаточные связи: позволяют обучать более глубокие сети, помогают бороться с проблемой исчезающего градиента, обеспечивают беспрепятственное распространение градиентов.
Интересный факт: Хотя параметры нормализации слоев составляют менее 0.1% от всех параметров модели, они играют критическую роль в трансфере знаний между доменами. Исследования показывают, что тонкая настройка только параметров нормализации слоев может быть достаточна для адаптации предобученной модели к новым задачам в условиях ограниченных данных.
Пошаговый анализ вычислительного процесса
Рассмотрим полный цикл обработки входной последовательности через трансформер для задачи машинного перевода:
- Входная последовательность (например, предложение на английском языке) токенизируется.
- Токены преобразуются в векторные представления через матрицу вложений.
- К вложениям добавляется позиционное кодирование для учета порядка токенов.
- Энкодер обрабатывает входную последовательность:
- Каждый токен проходит через механизм самовнимания, где вычисляются веса внимания между всеми парами токенов.
- Токены обновляются на основе взвешенной суммы значений других токенов.
- Обновленные представления проходят через FFN для дальнейшей обработки.
- Процесс повторяется для каждого из N слоев энкодера.
- Декодер генерирует выходную последовательность (перевод на другой язык) автореграссивно, токен за токеном:
- Начиная с токена начала последовательности, декодер применяет маскированное самовнимание к уже сгенерированным токенам.
- Затем применяется перекрестное внимание к выходу энкодера, позволяя декодеру фокусироваться на релевантных частях входной последовательности.
- После FFN получается прогноз для следующего токена.
- Процесс повторяется до тех пор, пока не будет сгенерирован токен конца последовательности или не будет достигнута максимальная длина.
- Выходная последовательность формируется из сгенерированных токенов.
Пример потока данных через трансформер:
1. Входное предложение: "I love machine learning"
2. Токенизация: ["I", "love", "machine", "learning"]
3. Преобразование в вложения и добавление позиционного кодирования
4. В энкодере:
- Токен "I" обращает внимание на все токены предложения
- Токен "love" аналогично взаимодействует со всеми токенами
- И так далее для каждого токена
5. Выход энкодера: обогащенные контекстом представления каждого токена
6. В декодере:
- Начинаем с токена "
" - Через перекрестное внимание декодер фокусируется на релевантных частях исходного предложения
- Генерируем первый токен перевода, например "Я"
- Для генерации следующего токена используем уже сгенерированные токены ["
", "Я"] - Продолжаем процесс до генерации токена "
"
7. Выходное предложение: "Я люблю машинное обучение"
Применения трансформеров
Трансформеры стали доминирующей архитектурой в различных областях обработки естественного языка и за ее пределами:
- Машинный перевод: оригинальное применение, где трансформеры установили новые стандарты качества.
- Языковое моделирование: GPT (Generative Pre-trained Transformer) и его варианты для генерации текста.
- Понимание языка: BERT (Bidirectional Encoder Representations from Transformers) для классификации текста, ответов на вопросы, и других задач понимания языка.
- Мультимодальные задачи: модели, работающие с текстом и изображениями, такие как DALL-E, Stable Diffusion, Midjourney.
- Биоинформатика: предсказание структуры белков (AlphaFold).
- Компьютерное зрение: Vision Transformer (ViT) для классификации изображений.
- Обработка звука: речевые модели, распознавание и синтез речи.
- Рекомендательные системы: для персонализации контента.
Ключевые варианты архитектуры трансформеров:
- Только энкодер: BERT, RoBERTa, используются для задач понимания языка.
- Только декодер: GPT, используются для генерации текста.
- Энкодер-декодер: T5, BART, используются для задач преобразования последовательностей (например, перевод, суммаризация).
Современное развитие: Активно развиваются эффективные реализации трансформеров с линейной сложностью, такие как Linformer, Reformer, и Longformer, которые позволяют обрабатывать очень длинные последовательности без квадратичного роста вычислительной сложности.
Пример работы и реализации
Рассмотрим пример генерации текста с использованием модели на основе трансформера, такой как GPT:
Пример генерации текста:
Входной текст (промпт): "Искусственный интеллект может"
Процесс генерации:
- Токенизация промпта: ["Искусственный", "интеллект", "может"]
- Преобразование токенов в вложения и добавление позиционного кодирования
- Обработка последовательности через слои трансформера
- Прогнозирование распределения вероятностей для следующего токена
- Выбор токена на основе этого распределения (например, "помочь")
- Добавление выбранного токена к контексту: ["Искусственный", "интеллект", "может", "помочь"]
- Повторение процесса для генерации следующих токенов
Возможный сгенерированный текст: "Искусственный интеллект может помочь решить множество сложных задач, от медицинской диагностики до оптимизации транспортных маршрутов. Современные модели машинного обучения способны обрабатывать огромные объемы данных и находить в них скрытые закономерности."
Важные аспекты при генерации текста:
- Температура (temperature): параметр, контролирующий случайность генерации. Более низкая температура делает генерацию более детерминированной, более высокая – более креативной.
- Top-k сэмплирование: рассматриваются только k токенов с наибольшей вероятностью.
- Nucleus сэмплирование (top-p): рассматриваются токены, суммарная вероятность которых составляет p.
- Запрещенные токены (banned tokens): можно запретить генерацию определенных токенов.
- Контролирование контекста: генерация может быть направлена с помощью контекста или дополнительных инструкций.
Практический совет: При использовании предобученных моделей трансформеров, часто более эффективно выполнять тонкую настройку только некоторых компонентов (например, слоев нормализации или последних нескольких слоев), вместо полной тонкой настройки всей модели, особенно при ограниченных данных.
Заключение и дальнейшие направления
Архитектура трансформеров произвела революцию в области глубокого обучения и обработки естественного языка, предоставив мощный инструмент для широкого спектра задач. Ключевые преимущества этой архитектуры:
- Эффективное улавливание дальних зависимостей в последовательностях
- Параллелизация вычислений, позволяющая ускорить обучение
- Масштабируемость, позволяющая создавать все более крупные и мощные модели
- Универсальность применения в различных доменах
Текущие направления исследований и развития:
- Эффективность: разработка архитектур с линейной или сублинейной сложностью для обработки очень длинных последовательностей.
- Интерпретируемость: улучшение понимания внутренних механизмов работы трансформеров.
- Комбинирование с другими архитектурами: гибридные модели, объединяющие преимущества трансформеров с CNN, RNN или другими архитектурами.
- Специализированные варианты: адаптация трансформеров для конкретных доменов и задач.
- Энергоэффективность: уменьшение вычислительных и энергетических требований.
- Мультимодальность: объединение и согласование разных модальностей данных (текст, изображения, звук, видео).
Несмотря на значительный прогресс, архитектура трансформеров продолжает развиваться, и исследования в этой области остаются активными. Понимание математических основ и механизмов работы трансформеров является ключом к разработке новых, более эффективных и мощных моделей в будущем.
Заключительная мысль: Трансформеры демонстрируют, как относительно простая идея – механизм внимания – может привести к революционным изменениям в области искусственного интеллекта. Это подчеркивает важность фундаментальных исследований и новых архитектурных подходов в развитии машинного обучения.